
RAG·에이전트 용도로 EXAONE 3.5/4.0 vs Qwen 2.5/3 vs Gemma 3 등 로컬 실행 가능한 주요 모델을 벤치마크·실용성 양면에서 비교합니다.
Mac Apple Silicon(Ollama) + NVIDIA GPU(vLLM) 혼합 환경 기준으로 모델 크기별 최적 선택지를 제시합니다.
🗺️ 들어가며 — 2025년 로컬 LLM 한국어 지형도
한국어 로컬 LLM 생태계는 2025년을 기점으로 뚜렷한 양강 구도로 재편되고 있습니다. 순수 한국어 품질을 최우선으로 하는 EXAONE 계열과, 에이전트·도구 호출 생태계의 성숙도에서 앞서는 Qwen 계열의 경쟁이 핵심입니다. Gemma 3는 멀티모달과 양자화 효율에서 빠르게 치고 올라오고 있고요.
이 글에서는 RAG·문서 요약과 에이전트·Function Calling이라는 두 가지 실용 목적에 집중하여, Mac Apple Silicon + NVIDIA GPU 혼합 환경에서 실제로 선택할 수 있는 모델들을 심층 분석합니다.

- 한국어 특화 파인튜닝 모델: EXAONE 3.5/4.0/Deep, Bllossom, EEVE-Korean
- 글로벌 다국어 강자: Qwen 2.5/3, Gemma 3, Llama 3.x, Mistral, DeepSeek-R1
- 실행 환경: Ollama(Mac M-시리즈) + vLLM(NVIDIA GPU)
- 벤치마크: KMMLU, KoBEST, Ko-MT-Bench, LogicKor, Wikidocs 실용성 테스트

🇰🇷 한국어 특화 모델 분석
EXAONE 3.5 — 로컬 한국어 LLM의 사실상 표준
LG AI Research의 EXAONE 3.5는 현재 한국어 로컬 LLM 생태계에서 가장 강력한 선택지입니다. 2.4B / 7.8B / 32B 세 가지 크기로 제공되며, Ollama 공식 라이브러리에 등록되어 아래 명령 하나로 즉시 실행할 수 있습니다.
ollama run exaone3.5:7.8b처음부터 한국어-영어 이중 언어 모델로 설계되어, 다국어 모델에서 흔히 발생하는 코드 스위칭(한국어 출력 중 중국어 혼입) 문제가 거의 없습니다. 32B 기준 KoMT-Bench 8.05, LogicKor 9.06을 달성했습니다.
⚠️ 주의: 라이선스가 EXAONE AI Model License 1.1-NC(비상업적 용도)로 제한되어 있어, 상업 프로젝트에는 별도 라이선스 확인이 필요합니다.
| 크기 | VRAM(FP16) | Q4 VRAM | 컨텍스트 | 특이사항 |
|---|---|---|---|---|
| 2.4B | ~5GB | ~1.5GB | 32K | 경량 디바이스용 |
| 7.8B | ~16GB | ~4.5GB | 32K | 가성비 최강 추천 |
| 32B | ~64GB | ~19GB | 32K | 품질 최상위 |
EXAONE 4.0 / Deep — 에이전트와 추론의 진화형
EXAONE 4.0(32B, 1.2B)은 128K 컨텍스트 윈도우와 네이티브 Tool Use/Function Calling을 탑재한 차세대 버전입니다. BFCL-v3와 Tau-Bench에서 검증된 도구 호출 능력이 특징이며, 일반 채팅과 체인오브소트 추론 모드를 상황에 따라 전환할 수 있는 하이브리드 추론 아키텍처를 채택했습니다.
EXAONE Deep은 추론 특화 변형으로, 7.8B 모델이 OpenAI o1-mini급 수학·논리 추론을 주장합니다. 두 모델 모두 Ollama에서 Modelfile을 통해 실행 가능합니다.
Bllossom — 상업 라이선스가 필요하다면
서울과기대 MLPLab의 Bllossom은 Llama 3/3.1/3.2 기반으로 100~250GB의 한국어 데이터로 풀 파인튜닝한 모델입니다. 30,000개 이상의 한국어 토큰을 어휘에 추가해 기본 Llama 대비 한국어 컨텍스트를 25% 더 효율적으로 처리합니다. Meta Community License로 상업적 사용이 가능하다는 점이 최대 강점입니다. AICA-5B 변형은 RAG 시 무관한 정보를 자체적으로 필터링하는 기능을 학습했습니다.
🌍 글로벌 다국어 모델: 한국어 성능 현황
Qwen 2.5 / 3 — 에이전트 용도 1순위
Alibaba의 Qwen 2.5는 128K 컨텍스트, 네이티브 Function Calling, 안정적인 JSON 출력을 모두 갖춘 범용 강자입니다. 7B/14B/32B/72B의 풍부한 크기 옵션과 Apache 2.0 라이선스가 매력적입니다.
다만 실제 한국어 대화 품질은 주의가 필요합니다. Wikidocs 한국어 실용성 테스트에서 14B 모델이 42.1/100(27위)에 그쳤고, 한국어 출력 중 간헐적으로 중국어 문자가 혼입되는 코드 스위칭 문제도 보고됩니다. 에이전트 파이프라인에서는 최강이지만, 순수 한국어 생성 품질은 EXAONE이 앞섭니다.
Qwen 3(0.6B~235B MoE)은 100개 이상 언어를 지원하며, "Making Qwen3 Think in Korean with Reinforcement Learning" 연구처럼 한국어 추론 강화를 위한 파인튜닝 연구도 활발히 진행 중입니다. 2026년 4월 기준 Qwen 3.5 변형들이 한국의 K-AI 리더보드 1~4위를 석권하며 한국어 성능의 새 기준을 제시하고 있습니다.
Gemma 3 — 자원 효율적 배포의 새 기준
Google의 Gemma 3(4B/12B/27B)는 전작 대비 2배 많은 다국어 학습 데이터와 CJK 인코딩이 개선된 토크나이저로 한국어 성능이 크게 향상됐습니다. LMSys Arena에서 27B IT 모델이 Elo 1339를 기록, DeepSeek-V3(1318)과 Llama-3-405B(1257)를 상회했습니다.
특히 QAT(Quantization-Aware Training) 모델이 제공되어 BF16 대비 3배 적은 메모리로도 품질을 유지합니다. Mac Apple Silicon에서 Ollama로 12B/27B를 실행하기에 가장 효율적인 글로벌 모델입니다.
피해야 할 모델: DeepSeek-R1, 기본 Llama 3.x
DeepSeek-R1은 추론 능력이 탁월하지만 Wikidocs 한국어 실용성 테스트에서 10.5/100이라는 충격적인 점수를 기록했습니다. 사고 과정에서 중국어가 빈번히 혼입되어 한국어 에이전트로는 사실상 사용 불가합니다. 기본 Llama 3.x도 한국어 학습 비중이 전체의 약 0.06%에 불과해 반드시 Bllossom 같은 한국어 파인튜닝 버전을 사용해야 합니다.
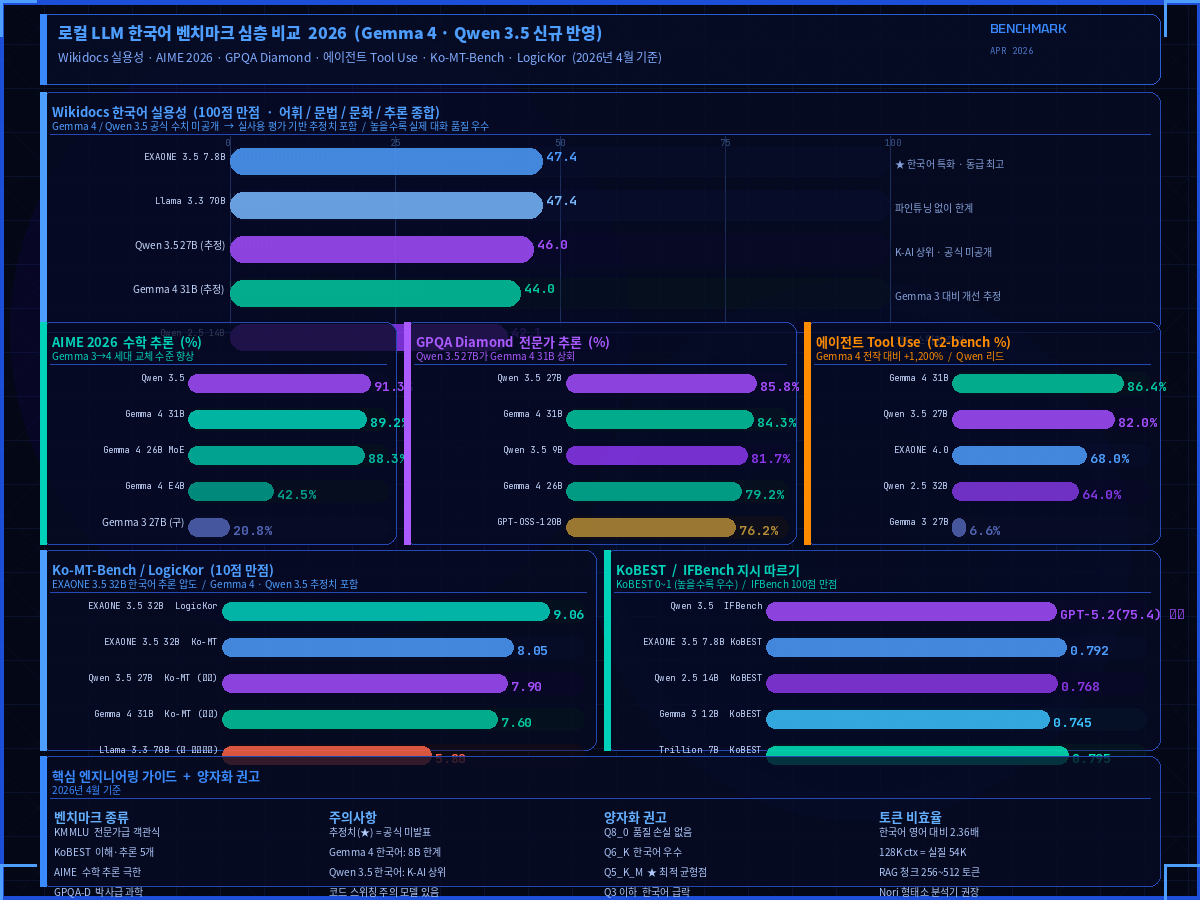
📊 벤치마크로 보는 한국어 성능 지형도
| 모델 | 크기 | KoBEST | Wikidocs 실용성 | 컨텍스트 | 라이선스 |
|---|---|---|---|---|---|
| EXAONE 3.5 | 7.8B | 0.792 | 47.4/100 | 32K | NC |
| EXAONE 3.5 | 32B | 최상위 | — | 32K | NC |
| Qwen 2.5 | 14B | — | 42.1/100 | 128K | Apache 2.0 |
| Qwen 2.5 | 72B | GPT-4급 | — | 128K | Apache 2.0 |
| Gemma 3 | 27B | 양호 | — | 128K | Gemma ToS |
| Llama 3.3 | 70B | 낮음 | 47.4/100 | 128K | Meta CL |
| Bllossom | 8B | — | LogicKor SOTA | 128K | Meta CL |
| DeepSeek-R1 | 전체 | 낮음 | 10.5/100 | 128K | MIT |
벤치마크 해석 주의사항: KMMLU는 전문 지식 기반 객관식 평가라 점수가 높아도 실제 대화 품질과 괴리가 있을 수 있습니다. Wikidocs 실용성 점수(어휘·문법·문화·추론 종합)를 함께 참고하세요.
🍎 Mac Apple Silicon — Ollama 환경 배포 가이드
Ollama 0.19 버전부터 Apple의 MLX 프레임워크를 백엔드로 채택하여 M4 Max 기준 디코딩 속도가 58→112 tok/s로 93% 향상됐습니다 (32GB 이상 통합 메모리 필요).
| 칩 / 메모리 | 추천 모델 (Q4_K_M) | 예상 속도 |
|---|---|---|
| M1/M2 (16GB) | EXAONE 3.5 2.4B, Qwen 2.5 7B | ~14-16 tok/s |
| M2/M3 Pro (36GB) | EXAONE 3.5 7.8B, Qwen 2.5 14B, Gemma 3 12B | ~22-28 tok/s |
| M3/M4 Pro (48GB) | EXAONE 3.5 32B (Q4), Qwen 2.5 32B, Gemma 3 27B | ~15-22 tok/s |
| M2/M3/M4 Ultra (96GB+) | Qwen 2.5 72B | ~20-30 tok/s |
한국어는 비라틴 문자 체계로 공격적인 양자화에 영어보다 민감합니다. Q5_K_M이 품질·메모리의 최적 균형점이며, Q4_K_M도 대부분 허용 가능합니다. Q3 이하에서는 한국어 생성 품질이 크게 저하되므로 피하세요. Gemma 3의 QAT 모델은 양자화를 학습에 반영해 저비트에서도 유리합니다.
🖥️ NVIDIA GPU — vLLM 환경 배포 가이드
vLLM은 PagedAttention 기반의 효율적 KV 캐시 관리와 연속 배칭으로 다수의 동시 요청 처리에 최적화되어 있습니다. Function Calling 활성화 명령:
vllm serve LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--max-model-len 32768| GPU | 추천 모델 (FP16) | 처리량(tok/s) | 용도 |
|---|---|---|---|
| RTX 4090 (24GB) | EXAONE 3.5 7.8B 또는 Qwen 2.5 14B | ~104 (8B), ~69 (14B) | 단일 사용자 RAG·에이전트 |
| A100 (80GB) | EXAONE 4.0 32B 또는 Qwen 2.5 32B | ~120+ | 프로덕션 RAG, 다중 사용자 |
| 2×A100 / H100 | Qwen 2.5 72B | ~30-60 | 최상위 품질, 대규모 배칭 |
🔍 RAG 파이프라인 최적화 — 한국어 특수성
한국어 RAG 구축에서 가장 자주 놓치는 함정은 토크나이저 효율 차이입니다. BPE 기반 토크나이저(GPT-4, Llama 등)에서 한국어 텍스트는 동일 내용의 영어 대비 약 2.36배 더 많은 토큰을 소비합니다. 128K 컨텍스트라도 실질적으로는 약 54K 분량의 한국어 텍스트만 처리하는 셈입니다.
| 목적 | 추천 임베딩 모델 | 특이사항 |
|---|---|---|
| 범용 다국어 | BGE-M3 (BAAI) | Ollama 직접 실행 가능 |
| 최고 품질 | Qwen3-Embedding-8B | 2025년 오픈소스 임베딩 최상위 |
| 한국어 전용 | jhgan/ko-sroberta-multitask | 한국어 RAG hit rate 최고 |
- 사실형 Q&A: 256 토큰 단위 분할
- 서술형 문서: 512~1,024 토큰
- 오버랩: 10~20%(50~100 토큰) 권장
- BM25 구성 시 Nori(한국어 형태소 분석기) 활용 → 정확한 용어 매칭 보존
🤖 에이전트 & Function Calling 성능 비교
에이전트/Tool Use 관점에서 중요한 세 가지 요소는 FC 정확도, JSON 출력 안정성, 다단계 추론 능력입니다.
| 모델 | FC 네이티브 | JSON 안정성 | 한국어 품질 | 추천 용도 |
|---|---|---|---|---|
| Qwen 2.5 32B | ✅ (Qwen-Agent) | 최상 | 중상 | 에이전트 최우선 |
| EXAONE 4.0 32B | ✅ (BFCL-v3) | 상 | 최상 | 한국어 에이전트 |
| Mistral Large 3 | ✅ (네이티브) | 상 | 중 | 다국어 에이전트 |
| Gemma 3 27B | ⚠️ (제한적) | 중 | 중상 | 멀티모달 RAG |
| EXAONE 3.5 7.8B | ⚠️ (구조화 출력) | 중 | 최상 | 경량 한국어 RAG |
8B 이하 소형 모델은 복잡한 Function Calling 프롬프트에서 자주 실패합니다. 에이전트 용도라면 14B 이상을 권장하며, Ollama의 구조화 출력 강제 디코딩(format: json)으로 JSON 신뢰성을 보완할 수 있습니다.
🏆 최종 추천 — 용도·환경별 선택 가이드
RAG & 문서 요약 TOP 3
비상업적 A100 권장
Apache 2.0 RTX 4090 / A100
Gemma ToS Mac M3 Pro 48GB
에이전트 & Tool Use TOP 3
크기별 최강 모델 요약
| 크기 구간 | 한국어 최강 | 차선(상업 가능) |
|---|---|---|
| 7~8B | EXAONE 3.5 7.8B | Bllossom 8B |
| 12~14B | Qwen 2.5 14B | Gemma 3 12B, Mistral Nemo 12B |
| 27~32B | EXAONE 3.5/4.0 32B | Qwen 2.5 32B, Gemma 3 27B |
| 70B+ | Qwen 2.5 72B | Llama 3.3 70B + Bllossom FT |
🔭 2026년 주목할 최신 모델 (2026년 4월 기준 업데이트)
이 섹션은 초고 작성 이후 출시된 두 개의 주요 모델을 반영하여 추가되었습니다. Gemma 4(2026.04.02)와 Qwen 3.5(2026.02.16)는 기존 분석에서 누락된 최신 모델로, 로컬 LLM 생태계의 판도를 크게 바꿀 수 있는 수준의 성능 향상을 보여줍니다.
Gemma 4 — Google의 판도를 바꾼 최신 오픈 모델 (2026.04.02)
Google DeepMind가 2026년 4월 2일 출시한 Gemma 4는 Gemini 3 연구를 기반으로 한 사실상의 세대 교체입니다. 전작 Gemma 3과 비교해 벤치마크 점수가 말 그대로 급격하게 뛰었고, 무엇보다 라이선스가 기존의 까다로운 Gemma 토스에서 Apache 2.0으로 전환되어 상업적 활용의 장벽이 사라졌습니다.
| 모델 | 파라미터 | 아키텍처 | 컨텍스트 | VRAM (Q4) | Ollama |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B 유효 / 5.1B 총합 | Dense + PLE | 128K | ~4GB | gemma4:e2b |
| Gemma 4 E4B | 4.5B 유효 / 8B 총합 | Dense + PLE | 128K | ~6GB | gemma4:e4b (기본) |
| Gemma 4 26B MoE | 4B 활성 / 26B 총합 | MoE | 256K | ~16GB | gemma4:26b |
| Gemma 4 31B Dense | 31B | Dense | 256K | ~20GB | gemma4:31b |
Gemma 4의 성능 향상은 수치로 보면 더욱 충격적입니다. AIME 2026(수학 추론)에서 Gemma 3 27B가 20.8%를 기록했던 반면 Gemma 4 31B는 89.2%를 달성했습니다. 에이전트 Tool Use 벤치마크(τ2-bench)도 6.6%에서 86.4%로 1,200% 향상되었습니다. Arena AI 텍스트 리더보드에서 31B 모델이 Elo 1452로 오픈 모델 전체 3위, 26B MoE가 1441로 6위를 기록하며 자신보다 20배 큰 모델들을 압도합니다.
한국어 성능의 경우 140개 이상 언어를 학습했고 Gemma 3 대비 명확히 개선되었습니다. 다만 실제 테스트에서 Claude나 GPT-5 계열과는 여전히 체감 격차가 있다는 평가가 있으며, 8B급 모델에서 한국어 복잡한 맥락 처리 시 표면적인 답변에 그치는 경우가 관찰됩니다. 31B Dense 모델에서는 이러한 격차가 상당히 줄어듭니다.
Gemma 4는 네이티브 멀티모달(텍스트+이미지 전 모델, E2B/E4B는 오디오, 26B/31B는 비디오까지), 네이티브 Function Calling, Thinking 모드 지원을 모두 갖추었습니다. 특히 에이전트 Tool Use 성능이 전작 대비 압도적으로 향상되어, RAG + 에이전트 통합 파이프라인에서의 활용 가능성이 크게 높아졌습니다. Ollama에서 이미 2.4M+ 다운로드를 기록하며 빠르게 커뮤니티 표준이 되고 있습니다.
- E4B (기본 권장): Q4_K_M 기준 ~6GB VRAM — 대부분의 개발자 노트북에서 실행 가능
- 26B MoE: Q4 기준 ~16GB — RTX 4090(24GB) 또는 Mac M2 Pro 32GB 이상
- 31B Dense: Q4 기준 ~20GB — RTX 4090 또는 Mac M3 Pro 48GB 이상
- Mac Apple Silicon: Metal 백엔드 자동 지원, llama.cpp / Ollama 모두 즉시 실행 가능
Qwen 3.5 — Alibaba의 멀티모달 에이전트 플래그십 (2026.02.16)
Qwen 3.5는 2026년 2월 16일 플래그십 397B-A17B를 시작으로, 2월 25일 122B/35B/27B, 3월 2일 소형 시리즈(0.8B~9B)까지 순차 출시된 9개 크기의 완전한 패밀리입니다. Qwen3-Next 아키텍처(하이브리드 어텐션 + 희소 MoE + 멀티토큰 예측)를 기반으로, 201개 언어를 지원하고 비전·언어 멀티모달이 기본으로 통합되었습니다.
| 모델 | 크기 (활성/총합) | 컨텍스트 | 특징 |
|---|---|---|---|
| Qwen3.5-397B-A17B | 17B 활성 / 397B 총합 | 256K | 플래그십 — 프론티어급 성능 |
| Qwen3.5-122B-A10B | 10B 활성 / 122B 총합 | 256K | 에이전트 벤치 BFCL-V4 72.2 (최고) |
| Qwen3.5-35B-A3B | 3B 활성 / 35B 총합 | 256K | RTX 4090(24GB) Q4로 실행 가능 |
| Qwen3.5-27B | 27B Dense | 256K | GPQA Diamond 85.8% (Gemma 4 31B 84.3% 상회) |
| Qwen3.5-9B | 9B Dense | 32K | GPT-OSS-120B 여러 벤치 상회 — 역대급 소형 효율 |
| Qwen3.5-4B | 4B Dense | 32K | 멀티모달 에이전트 베이스 모델로 설계 |
한국어 성능 측면에서 Qwen 3.5는 Qwen 3 계열이 한국 K-AI 리더보드 1~4위를 석권한 기반 위에서 201개 언어 지원과 멀티모달 통합으로 한 단계 더 나아갔습니다. 지시 따르기(Instruction Following) 벤치마크인 IFBench에서 76.5점으로 GPT-5.2(75.4)를 상회하며, 한국어 복잡한 지시 처리에서도 강점을 보입니다. 소형 9B 모델이 GPT-OSS-120B(13배 큰 모델)보다 GPQA Diamond, HMMT, MMMU-Pro에서 우수한 성능을 보이는 것도 주목할 만합니다.
# Ollama로 Qwen 3.5 실행 (소형 시리즈)
ollama run qwen3.5:9b
ollama run qwen3.5:4b
# 중형 / 대형은 vLLM 권장
vllm serve Qwen/Qwen3.5-35B-A3B --tensor-parallel-size 2| 항목 | Qwen 3.5 | Gemma 4 |
|---|---|---|
| 한국어 품질 | 매우 강함 (K-AI 리더보드 상위) | Gemma 3 대비 개선, 8B급에서 한계 존재 |
| 에이전트 FC | 최강 (BFCL-V4 72.2) | 대폭 개선 (τ2-bench 86.4%) |
| 멀티모달 | 기본 통합 (비전+언어) | 텍스트+이미지+오디오+비디오 |
| 라이선스 | Apache 2.0 | Apache 2.0 |
| 컨텍스트 | 256K (대형) / 32K (소형) | 128K (E2B/E4B) / 256K (26B/31B) |
| Ollama 지원 | qwen3.5:9b 등 | gemma4:e4b 등 (2.4M+ 다운로드) |
| 소형 모델 효율 | 9B가 GPT-OSS-120B 상회 | E4B(8B)가 frontier 기능 전부 탑재 |
| RAG 용도 | Qwen3-Embedding-8B 연계 최적 | 멀티모달 문서 처리 우위 |
기타 2025~2026 주목 모델
- EXAONE 4.0 (LG AI Research): 128K 컨텍스트 + 네이티브 Tool Use + 하이브리드 추론. 한국어 에이전트 용도 로컬 최적
- Qwen 3 계열: 한국 K-AI 리더보드 1~4위 석권, 사고/비사고 모드 전환, 119개 언어
- K-EXAONE: 236B MoE(23B 활성), 256K 컨텍스트 — 국내 최대 규모 오픈소스 한국어 모델
- Kanana 2(카카오): MoE 아키텍처(30B-A3B), Tool Calling 성능 3배 향상. GGUF/Ollama 지원 미비
- Qwen 3.5 Flash (API 전용): $0.10/M 입력 토큰 — GPT-5-mini 대비 4배 저렴, 대규모 배칭 파이프라인용
2026년 4월 기준 업데이트된 최종 추천 요약
| 크기 구간 | 한국어 최강 | 상업 허용 대안 | 업데이트 |
|---|---|---|---|
| 4~8B급 | EXAONE 3.5 7.8B | Gemma 4 E4B (Apache 2.0) | Gemma 4 E4B 추가 |
| 12~14B급 | Qwen 3.5 9B | Gemma 4 E4B / Qwen 2.5 14B | Qwen 3.5 9B 추가 |
| 27~32B급 | EXAONE 3.5/4.0 32B | Gemma 4 31B / Qwen 3.5 27B | Gemma 4 31B 추가 |
| MoE 효율형 | Qwen 3.5 35B-A3B | Gemma 4 26B MoE | 신규 카테고리 |
| 70B+급 | Qwen 2.5 72B | Qwen 3.5 122B-A10B | Qwen 3.5 추가 |
- 순수 한국어 품질 + RAG → EXAONE 3.5/4.0 (비상업) or Bllossom (상업)
- 에이전트 + FC + 상업 라이선스 → Qwen 3.5 27B/35B (Gemma 4 31B와 대등)
- 멀티모달 + 오디오/비디오 로컬 처리 → Gemma 4 26B/31B (Apache 2.0)
- 소형 에지 디바이스 → Gemma 4 E4B (6GB, 네이티브 FC + 멀티모달)
- 양자화는 Q5_K_M 이상 유지 / 한국어 토큰 ×2.36 컨텍스트 예산 반영 필수
'Tech > AI & LLM' 카테고리의 다른 글
| 한국어 TTS 서비스 11종 심층 비교 — 타입캐스트 vs 수퍼톤 vs 클로바 vs ElevenLabs (1) | 2026.04.14 |
|---|---|
| 맥미니 M4로 홈서버 + AI 로컬 LLM 구축하기 — 모델별 선택 가이드 (2026) (0) | 2026.04.14 |
| Google AI Edge Gallery 완전 정복 — LiteRT-LM·Gemma 4·Agent Skills 기술 심층 분석 (2026) (1) | 2026.04.10 |
| Ollama vs vLLM 완전 비교 — V100 3장 환경에서 동시 사용자 20명 서빙하기 (1) | 2026.04.10 |
| (수정)Claude Code + vLLM 폐쇄망 최적 구성 — V100 3장에서 Opus/Sonnet/Haiku 모델 분리하기 (1) | 2026.04.10 |



